Introduisons une application concrète de l’intelligence artificielle qui s’inscrit dans le prolongement de notre exploration de l’IA comme force transformatrice dans les industries traditionnelles. Dans cet esprit, nous allons développer un programme Python simple, destiné à illustrer comment l’IA peut être utilisée pour analyser et optimiser la structure de coûts d’une entreprise. Ce programme sera une première approche pour les professionnels et les curieux désireux de comprendre l’application pratique de l’IA sans se perdre dans la complexité technique.
Objectif du programme
Notre but est de créer un ensemble de données factices représentant divers coûts opérationnels d’une entreprise. Ensuite, nous appliquerons une technique d’IA, pour identifier les zones potentielles d’optimisation des coûts. Ce processus illustrera comment l’IA peut révéler des insights cachés dans les données, sous condition d’être associée avec une personne experte de son domaine, permettant ainsi une prise de décision éclairée sur où et comment réduire les dépenses.
Générons des données factice d’étude
import pandas as pd
import numpy as np
np.random.seed(42) # Pour la reproductibilité
# Générons des données plus complexes, incluant des informations superflues
data = {
'Type de coût': np.random.choice(['R&D', 'Marketing', 'Production', 'Administration'], size=100),
'Montant': np.random.randint(1000, 50000, size=100),
"Nombre d'employés impliqués": np.random.randint(1, 100, size=100), # Donnée potentiellement superflue
'Heures de travail': np.random.randint(1, 40, size=100), # Autre donnée superflue
'Efficacité': np.random.rand(100) # Potentiellement pertinente selon le contexte
}
df = pd.DataFrame(data)
print(df.head())Sélection et analyse des données par un expert
Un expert intervient ici avec le datascientist pour déterminer quelles caractéristiques (features) sont essentielles pour l’analyse de clustering. Supposons que l’expert a décidé de se concentrer uniquement sur Montant et Efficacité, jugeant les autres caractéristiques comme non pertinentes pour cette analyse spécifique.
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# L'expert sélectionne les caractéristiques pertinentes
features = ['Montant', 'Efficacité']
# Application du clustering KMeans sur les caractéristiques sélectionnées
kmeans = KMeans(n_clusters=4, random_state=42)
clusters = kmeans.fit_predict(df[features])
# Visualisation des résultats
plt.scatter(df['Montant'], df['Efficacité'], c=clusters, cmap='viridis')
plt.xlabel('Montant')
plt.ylabel('Efficacité')
plt.title('Clustering basé sur le Montant et l\'Efficacité')
plt.show()
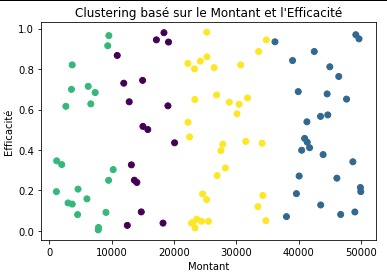
En analysant cette image, on se rend compte qu’il est possible de regrouper les ensembles d’activité similaires dans la structure de coût en considérant le montant et l’efficacité de nos données. Ainsi, par cette approche de clustering, il est possible de définir des priorité et des stratégies adaptées à chacun de ces centre de coût, plutôt que de chercher à appliquer la même démarche partout.
Ce processus de sélection des caractéristiques rappelle l’importance de l’expertise humaine dans l’analyse des données. Les experts aident à naviguer dans les des données complexes, en extrayant des informations pertinentes pour des insights significatifs.
Pour aller plus loin
Bien sûr, le cas présenté ici est purement factice. Or dans la réalité les données entremêlées sont beaucoup plus complexes à analyser. Une des manières que démêler justement cette complexité consiste à retrouver de manière automatique ce qui génère qu’un centre de coût est élevé ou pas. À partir de là, plutôt que d’agir directement sur ce qui coûte le plus, ce qui demande généralement le plus de ressources, je trouve plus malin de remonter 5 dominos plus tôt et d’utiliser beaucoup moins de ressources pour obtenir le même effet.
Ce qu’il faut retenir ici, c’est que c’est possible. Je vous encourage à jouer avec le jeu de données en ajoutant ou retirant des caractéristiques, en changeant le nombre de clusters, ou en explorant différentes méthodes d’analyse pour voir comment ces modifications affectent les résultats. Projetez-vous ensuite sur vos propres données !
Et si vous êtes sur Besançon et que vous voulez en discuter un peu plus, n’hésitez pas à me contacter !